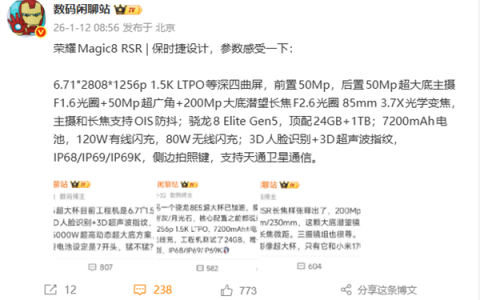
快科技8月4日消息,小米正式发布并开源声音理解大模型MiDashengLM-7B,该模型是小米“人车家全生态”战略的关键技术组件。
MiDashengLM通过统一理解语音、环境声与音乐的跨领域能力,不仅能听懂用户周围发生了什么事情,还能分析发现这些事情的隐藏含义,提高用户场景理解的泛化性。
基于MiDashengLM的模型通过自然语言和用户交互,为用户提更人性化的沟通和反馈,比如在用户练习唱歌或练习外语时提供发音反馈并制定针对性提升方案,又比如在用户驾驶车辆时实时对用户关于环境声音的提问做出解答,其应用场景有广阔的空间。
结合高效的推理部署性能,MiDashengLM将广泛赋能智能座舱、智能家居等场景,推动多模态交互体验升级。
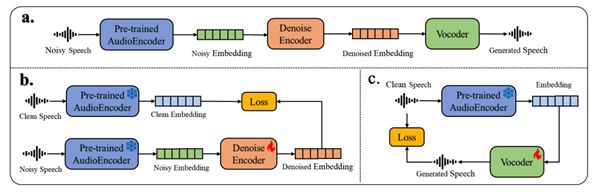
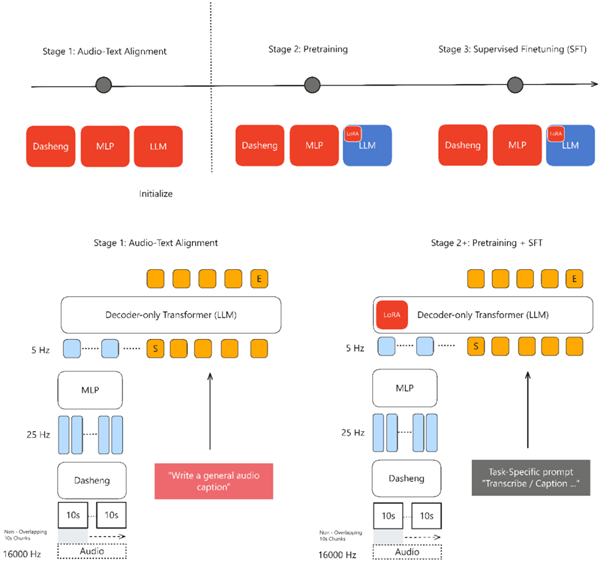
基于Xiaomi Dasheng音频编码器和Qwen2.5-Omni-7B Thinker自回归解码器构建,通过通用音频描述训练策略,实现对语音、环境声音和音乐的统一理解。
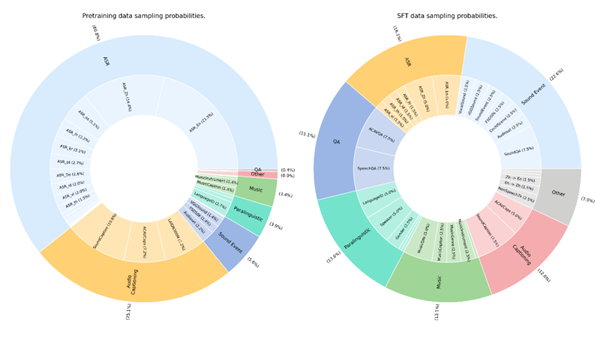
训练数据100%来自公开数据集,涵盖五大类110万小时资源,以Apache License 2.0协议发布,支持学术和商业应用。
核心优势:
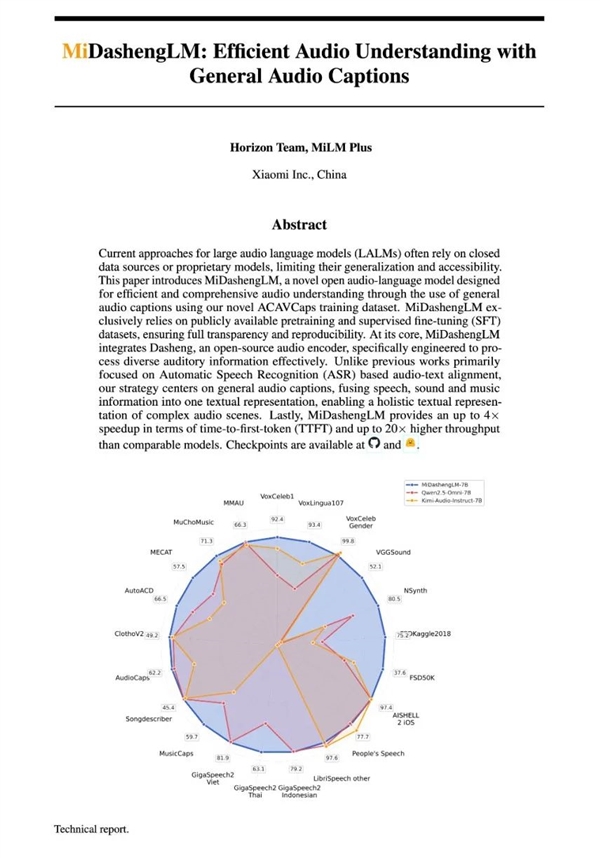
性能领先:在22个公开评测集上刷新多模态大模型最好成绩(SOTA),在音频描述、声音理解、音频问答任务中表现突出,同时具备可用的语音识别能力。其音频编码器Xiaomi Dasheng在X-ARES Benchmark多项关键任务,尤其是非语音类理解任务上显著优于Whisper。
推理效率高:单样本推理的首Token延迟(TTFT)仅为业界先进模型的1/4;同等显存下数据吞吐效率是业界先进模型的20倍以上,80GB GPU上处理30秒音频并生成100个token时,batch size可达512,而同类模型在batch size 16时即显存溢出。
训练范式革新:采用通用音频描述对齐范式,通过非单调全局语义映射,学习音频场景深层语义关联,避免传统ASR转录数据对齐的局限,数据利用率高,还能捕捉说话人情感、空间混响等关键声学特征。
原创文章,作者:admin,如若转载,请注明出处:http://www.kandianxun.com/internet/42327.html